Some sort of validation
Datapult is a social media tool. At least that’s the idea at this point. The ideal users of it are people on Twitter who are interested in and share information about cryptocurrency. These people are part of “crypto Twitter” as it’s known in some circles. This is the theory at this point anyway, based purely on my initial questions as to “why doesn’t something like this exist?“. No data is driving this line of questioning. It’s just an intuition based on my experience in the space. It’s based on also my own (very selfish) motivation to make something like Datapult so I can use it!
We’re at the point in the design and direction of the project, beyond just casually thinking about it, or doing some rough sketches about the UI.
We’re beyond this now…

Data, any at all
Since Datapult is a tool for social media, and Twitter holds the biggest number of potential users for the product, it makes to spend time analyzing what’s going on there. More than just casually, but with actual numbers and examples.
I wanted to know the following:
- Are people in “Crypto Twitter” sharing images at all or do they already use some other sharing service?
- How many are shared (roughly) a day?
- If we filter to iOS only (since Datapult is initially an iOS only app), or verified accounts only, what does that do to the numbers?
- (bonus) Based on the tweets we find, are there any people we would want to reach out to to be early alpha or beta testers of Datapult?
How to get data from Twitter
First we have to sign up for a Developer account. This involves providing some information of how you’re planning on using the data and API. You also have to agree to the terms of usage, etc… Our use case is just read-only analysis of public data and we won’t be interacting with any accounts or tweets so approval of our developer account and application was instant.
Once you start looking into the documentation for the API you’ll see there’s a new V2 (“new” is two years old in Twitter timescale) API in “early access” that they suggest we use. This is what we will use for our analysis. It looks like exactly what we need to start pulling the data we’re looking for.
We want to query twitter by stream so, in theory we can set up a lightweight service to sit and collect data for us over time (rather than query it in batches when accessing historical data). Thankfully there’s good documentation on how to use the stream API, and even some example apps. For my initial research I was looking just to prove out that I could get the data I wanted, tweets with pictures in them (not links to images hosted on other media sites).
An answer!
Looking through the documentation on how to build a rule I found that a good starter query is as simple as ethereum has:media -is:retweet. While this does not capture all of Crypto Twitter, Ethereum is the most popular and widely used. It’s a great place to start. And as it turns out there’s even a very simple Glitch app I can plug this query (and by Auth token) into to get a stream of tweets right away. To use this you simply “Remix” it and then edit the .env settings and you’re up and running! Neat.
Here’s what the app feed looks like with the filter rules applied:
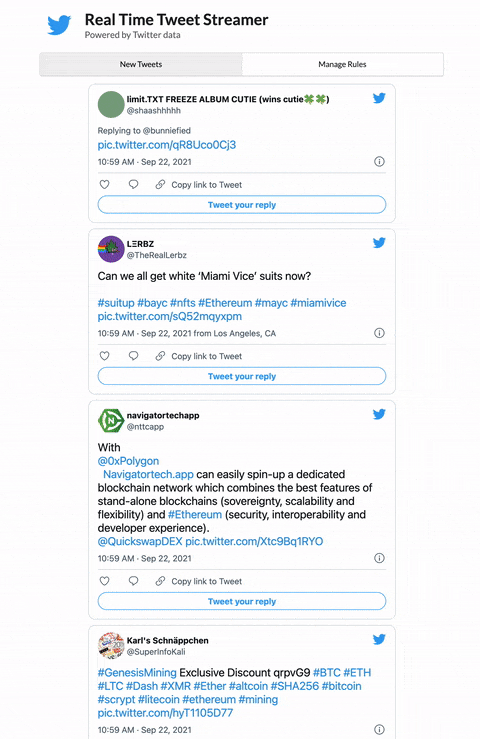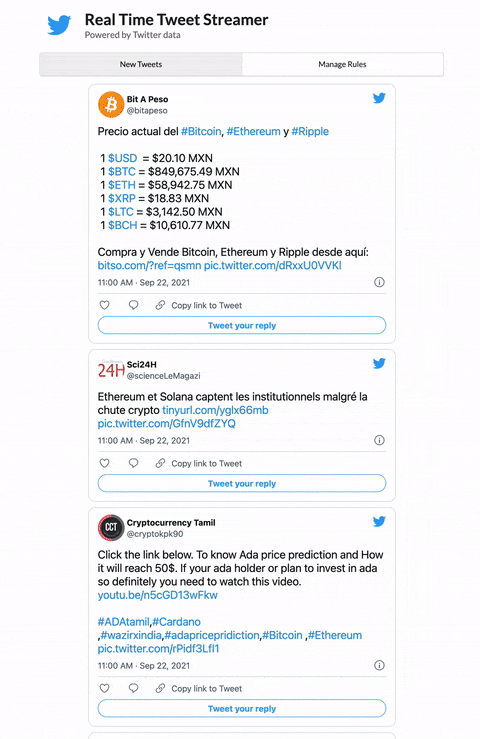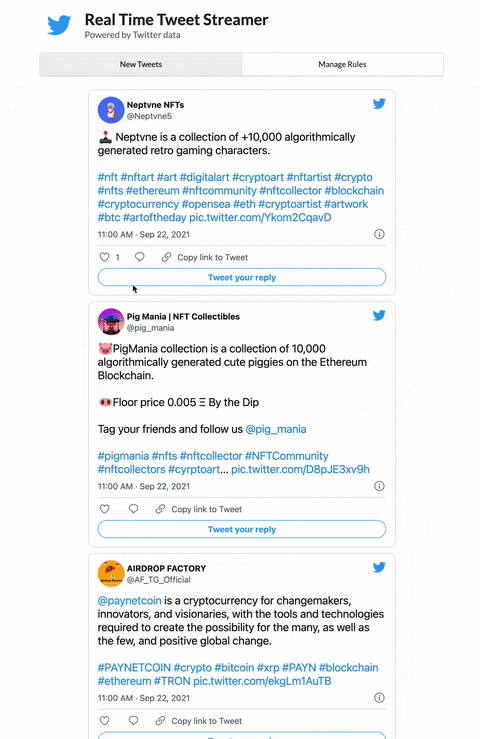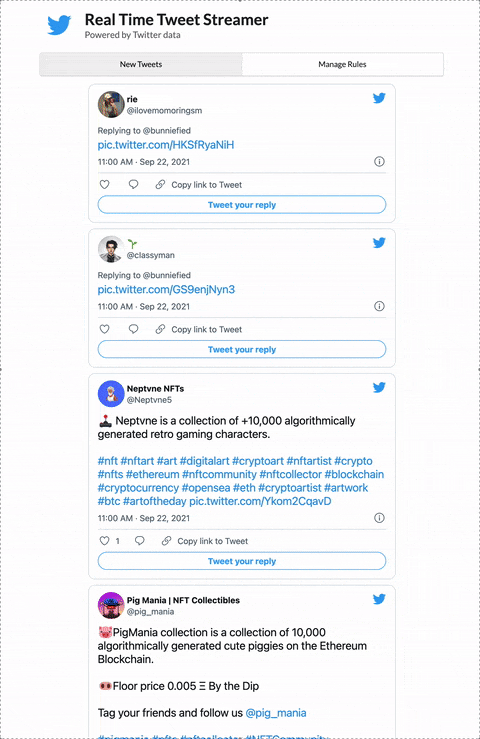
The actual pictures shared by the authors of these tweets don’t show up in this view (would be too much bandwidth to pull down all the images at the rate these are coming in) BUT you can see the pic.twitter.com/blah link at the end of the tweet. That’s what we’re looking for, a native Twitter image. One uploaded through the browser or Twitter app.
More to follow…
For now this is a good start. More to come in other articles as we work our way up the sophistication curve with our use of Twitters data streams. What we were able to do is get an answer to Question 1, that yes, people on Crypto Twitter use the native Twitter image feature. Might seem very obvious to some but it’s always good to check your base assumptions. To quote Mark Twain - “It ain’t what you don’t know that gets you into trouble. It’s what you know for sure that just ain’t so.”
If you’re not familiar with the Datapult project you can read more about it here. Follow along on Twitter when we drop updates here on our website.
